「跨本体全身運動データ工場」が正式稼働、橋介数物が運動制御分野のデータ空白を埋める
データ工場
01
はじめに
私たちは、モーション設計、同期キャプチャ、クロスエンボディメント・リターゲティング、データ拡張からトレーニングフィードバックに至る一連のプロセスを統合したクロスエンボディメント全身運動データファクトリー(Cross-Embodiment Whole-Body Motion Data Factory)を構築しました。データファクトリーは継続的に稼働するインフラとして、ヒューマノイドのロボットオペレーティングシステムにデータの「燃料」を供給し、システム内の全身運動モデルがクロスエンボディメントで、トレーニング可能、かつ再利用可能なデータ資産を継続的に獲得できるようにします。
モデル能力の向上は、データによる制約をますます顕著に受けるようになっています。データ規模が不足していると、モデルが十分な種類のアクションをカバーできず、データの品質が不安定であれば、モデルは誤った接触関係や身体の協調方法を学習してしまいます。さらに、データが異なるエンボディメント間で再利用できなければ、ロボットのハードウェアが変更されるたびに、多くのトレーニング資産をゼロから再生産しなければならなくなります。
汎用的な全身運動モデルにとって、データはもはや単なるトレーニング用の素材ではなく、能力の限界を決定する重要な資産そのものです。
今回のパイロットプロジェクトと、過去2年間にわたる様々な脚式ロボットでのエンジニアリング実践に基づき、私たちはデータファクトリーを内部検証の段階から、正式な大規模建設へと進めています。本インフラが解決するのは、どのように継続的なモーション計画、マルチソース信号の同期キャプチャ、クロスエンボディメント・リターゲティング、物理検証、データ拡張を行い、そのトレーニング結果を次の生産サイクルへとフィードバックするかという課題です。
この記事では、運動制御データファクトリーに関する現段階での考察を共有します。クロスエンボディメント全身運動データとは何か、なぜそのために専用のファクトリーを建設する必要があるのか、そしてそのファクトリーの内部をどのように稼働させるべきかについて解説します。
02
運動能力の観点から、どのようなデータが必要か
「どのようなデータが必要か」に答えるには、まず「私たちはどのような運動能力を求めているのか」に答えなければなりません。
汎用全身運動モデルに対して私たちが求めるのは、上位ではマルチモーダルな動作意図と互換性があり、下位では異なるエンボディメント(ハードウェア)に対応し、安全で信頼性が高く、かつ複雑な環境において進化し続けることのできる運動能力です。
この能力は、データに対してより高い要求を突きつけます。モデルが必要とするのは、全身の協調、タスクの意図、接触関係、環境のコンテキスト、物理的な実現可能性、そしてクロスエンボディメントでの再利用価値を同時に保持するデータです。
しかし、既存のデータ形態を個別に見た場合、これらの要求を自然に満たすことは困難です。
モーションキャプチャデータは、人間の運動状態を正確かつ構造化して記録できますが、環境情報や人と環境との間の正確なインタラクションが欠落しています。
テレオペレーション(遠隔操作)データは特定のロボット本体に厳密に紐づいており、ハードウェアが変わると再利用価値が著しく低下します。
一人称視点(エゴセントリック)動画は、手先(エンドエフェクタ)と物体のインタラクションに集中しているため、体幹、下肢、重心、および接触間の全身的な協調関係を完全に表現できません。
三人称視点動画は動作全体を捉えられますが、そこから正確で妥当な人間の動作を抽出するのは困難です。これらのデータはそれぞれ独自の価値を持っていますが、単独では汎用全身運動モデルが必要とするデータの閉ループを支えるには不十分です。
この判断に基づき、私たちは真に汎用全身運動モデルのトレーニングに向けたデータ資産を、クロスエンボディメント全身運動データ(Cross-Embodiment Whole-Body Motion Data, CWM)と定義し、CWMが少なくとも以下の4つの特性を同時に満たすことを要求しています。
クロスエンボディメント・リターゲッタビリティ(Cross-embodiment retargetability)
同一の動作シーケンスを、統一された処理パイプラインを通じて、リンクの長さ、関節構成、質量分布、駆動能力が著しく異なる多様なターゲット本体において、物理的に自己整合性のあるトレーニングサンプルとして出力できなければなりません。これは、元のデータ自体が、特定のロボットの関節空間に固定されるのではなく、異なるエンボディメントへの統一的な構成マッピングをサポートするのに十分なトポロジーおよび運動学の情報を備えている必要があることを意味します。ロボットのハードウェアは継続的にアップデートされます。もしデータが特定の世代の機体だけにしか対応していなければ、その機体とともに減価償却されてしまいます。CWMは、データの価値を人間の全身の運動セマンティクスと転移可能な法則に結びつけることで、単一のデータを複数世代のハードウェアにわたって繰り返し活用できるようにします。
全身の網羅性(Whole-body coverage)
データは、体幹、四肢、手、指、およびそれらの協調関係を完全に表現する必要があり、上半身の手先軌道や下半身の歩行パターンだけを保存するのでは不十分です。実際のタスクは、多くの場合、局所的な動作の単純な組み合わせではありません。例えば「しゃがんで物を拾う—抱え上げる—向きを変えて歩く」という一連の動作には、下肢の支持、重心移動、体幹の姿勢、腕のリーチ調整、指の把持、および接触の切り替えが同時に絡み合っています。身体のこれらすべての部位の結合関係を全体として記録して初めて、モデルは移動、操作、姿勢変化の間の協調法則を学習することができます。
物理的実現可能性(Physical feasibility)
適格なデータは、単に運動学的に滑らかで合理的であるだけでなく、ターゲット本体における動力学的な物理的実現可能性を備えている必要があります。空中浮遊、突き抜け、滑り、不安定性、モータートルク制限超過などの問題が発生してはなりません。これは、CWM資産が候補軌道からトレーニングサンプルへと格上げされるための厳格な判断基準です。
マルチモーダル性(Multi-source augmentability)
CWMデータは、収録段階で人間の動作、セマンティックラベル、一人称視点動画、三人称視点動画、環境アセット、物体アセットを同期してキャプチャし、動作に完全な身体、タスク、およびシーンのコンテキストを付与します。その後、私たちはシミュレーション環境でデータを再生して拡張を行い、カメラ位置のカスタマイズ、シーンや物体のテクスチャの変更、全身の接触力や運動状態のキャプチャを通じて、単一のキャプチャをマルチアングル、マルチシーン、マルチフィジカル状態のトレーニングサンプルへと拡張します。
これら4つの特性を満たすCWMデータは、単なるキャプチャ作業だけで得られるものではありません。これこそが、私たちがクロスエンボディメント全身運動データファクトリーを建設する出発点となっています。
03
なぜデータファクトリーを建設するのか
私たちはCWMデータが何を指すかを定義しましたが、モデルのトレーニングにおいて「適切な」データがあるだけでは不十分です。データの規模も同様に極めて重要であり、この点は大規模言語モデル(LLM)の分野ですでに共通認識となっています。
Generalist AIの研究では、VLA(Vision-Language-Action)モデルにおいても明確なデータのスケーリングロー(Scaling Law)が存在することが示されています。また、SONICにおいても、ヒューマノイドの全身運動トラッキングにおいて、運動データ量の拡大が運動制御能力の著しい向上をもたらすことが体系的に検証されています。全身運動制御にとって、これはデータがいくつかの標準的な動作をカバーするだけでは不十分であり、歩行、旋回、しゃがみ、運搬、つかみ、支持、障害物回避、バランス回復、接触切り替えなど、膨大な連続動作の組み合わせをカバーしなければならないことを意味します。
私たちの内部的な判断では、真に汎用的な全身運動モデルをトレーニングするには、最終的に数十万時間規模の高品質なCWMデータが必要です。この規模を前にすると、少量のデータには長期的なトレーニング価値がほとんどなく、真に価値があるのは継続的に拡張できるデータの規模です。
同時に、データの多様性も極めて重要です。なぜなら、どれほど多くの歩行データがあっても、バク転ができるモデルを訓練することはできないからです。全身運動データの複雑さは、単に「動作が多ければ多いほど良い」というわけではなく、正しいデータレシピと厳格なデータ品質管理が不可欠であるという点にあります。
モデルは、十分な数の動作カテゴリ、接触状態、タスクセマンティクス、環境変化、およびターゲット本体の差異を目にする必要があります。同時に、個々のデータはクレンジング、アノテーション、リターゲティング、および物理検証を経る必要があります。さもなければ、大規模なデータは簡単に大規模なノイズへと化してしまいます。足元の滑り、身体の突き抜け、浮遊、不安定性、トルク制限超過などの問題は、モデルの品質を直接低下させるデータ汚染であり、これらはモデルに誤った接触関係、誤った身体協調方法、そして実行不可能な制御パターンを学習させてしまいます。
この基準は、外部データが主力を担うことはできないことをも意味しています。公開されているモーキャプータデータやインターネットの動画は補完として利用できますが、数量と品質の両面において、汎用全身運動モデルのトレーニングを支えるには不十分です。
したがって、CWMデータの生産は、キャプチャをその一環とする工業的な生産システムとして設計されなければなりません。設計された動作がトレーニングセットに組み込まれるまでには、品質検査、クロスエンボディメント・リターゲティング、動力学およびシミュレーション拡張、セマンティックアノテーション、そしてモデルトレーニング側からのフィードバック閉ループを経る必要があります。
この生産ラインは、データのレシピ、生産プロセス、そして品質基準を同時に定義する必要があります。どの動作を優先的にカバーすべきか、どのシーンや接触状態が最も枯渇しているか、どのターゲット本体の検証が必要か、どのサンプルを除外すべきか、そしてどのデータがトレーニングにおいて最も高い収益をもたらしたかを継続的に追跡し、フィードバックする必要があります。データ規模が大きくなるほど、手作業の経験に頼ることはできなくなります。モデルの目標が汎用的になるほど、再現可能、監査可能、かつ反復可能な生産プロセスが必要になります。
これこそが、CWMデータファクトリーの核心的な価値です。安定した環境、設備、ワークフロー、専門チーム、そして品質検査システムを用いて、汎用全身運動データをサステナブルな生産能力へと変えること。
プロのモーションデザイナーがモーション体系を定義し、キャプチャチームが高品質な同期収録を担当し、エンジニアリングチームがクレンジング、フォーマット変換、リターゲティング、およびシミュレーション再生を行い、アルゴリズムチームが物理検証、トレーニングフィードバック、データスクリーニングを実施し、品質管理チームが使用不可能なサンプルをトレーニングセットから排除します。
このようなファクトリーレベルの体系があって初めて、十分な規模、精度、クリーンさを備え、モデルのトレーニングやロボットのアップデートに合わせて継続的に更新できるCWMデータ資産を生み出し続けることが可能になります。
04
データファクトリーは「収録スタジオ」ではなく、一つの「インフラ」である
橋介数物のクロスエンボディメント全身運動データファクトリーは、CWMデータ資産の生産プロセス全体をカバーするフルプロセスのインフラです。
本ファクトリーはモーション設計から始まり、モーションカテゴリ、接触状態、タスクシーンを明確にします。キャプチャ段階では、人間の動作、ビデオ、接触、環境、物体など、マルチソースのデータを同期的に取得します。その後、クロスエンボディメント・リターゲティング、物理検証、シミュレーション拡張を経て、生の素材をトレーニング可能なサンプルへと変換します。最後に、トレーニングからのフィードバックを用いてデータレシピを継続的に修正します。
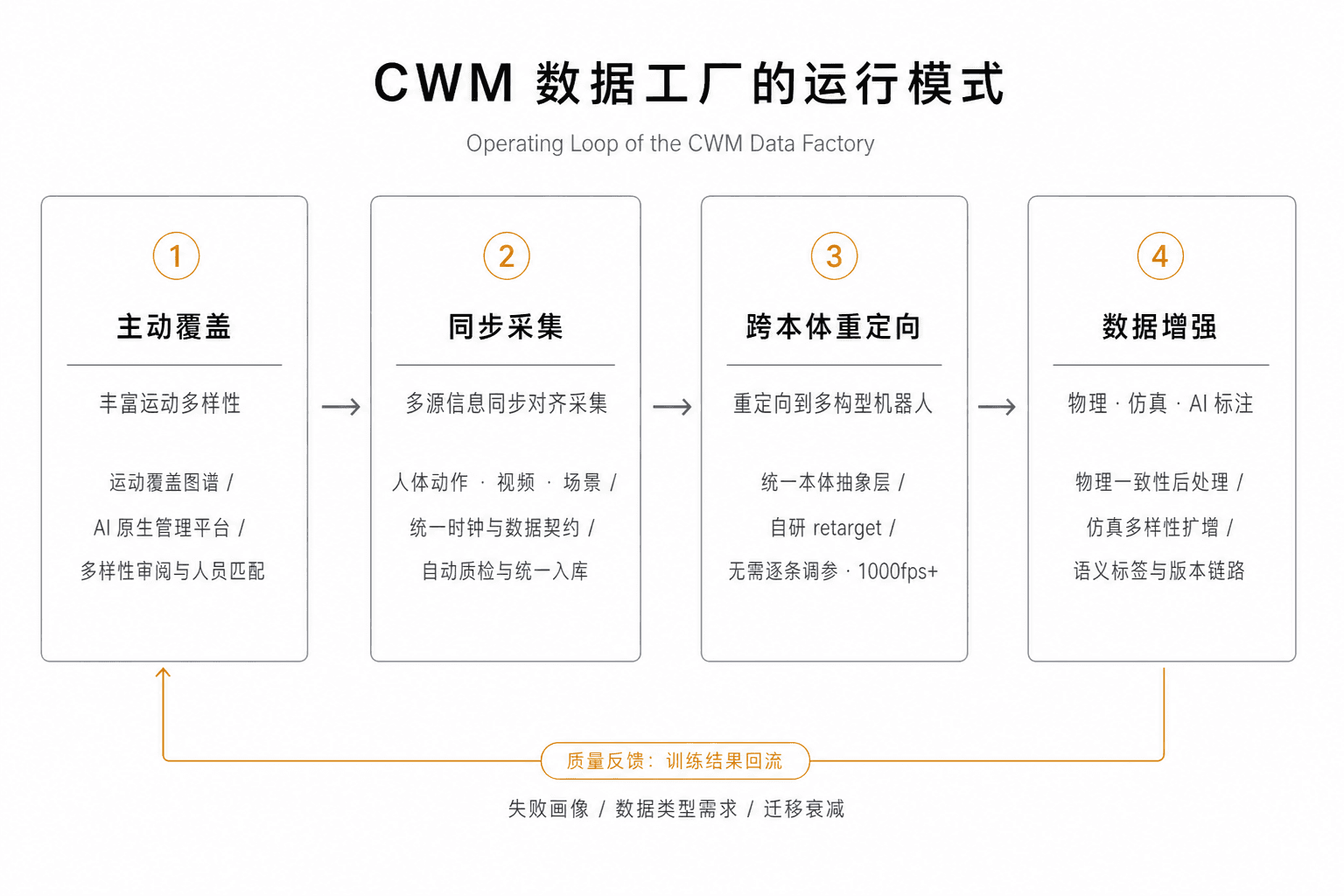
能動的カバレッジ:運動の多様性を豊かにする
データファクトリーが最初に答えるべき問いは、「何をキャプチャするか」です。汎用的な全身運動モデルは、継続的に拡張され、身体の協調方法をカバーする運動空間を学習する必要があります。この空間は単なる動作カタログの積み重ねであってはならず、複数の相互に独立した主軸に沿ってサステナブルに埋められる必要があります。
能力次元の横方向への展開
キャプチャ計画は、動作名で適当に数を合わせるのではなく、身体の使い方によって整理されるべきです。移動、姿勢遷移、肢体協調、接触切り替え、および物体操作といった基本次元は、その後に構築される複雑な能力の土台となります。私たちが関心を持っているのは、身体がどのように呼び出されるか、異なる部位がどのように協調するか、重心や接触がどのように変化するかであり、特定の個別の動作がキャプチャされたかどうかではありません。
複雑な地形、複数人のインタラクション、および環境インタラクション
これら3つのシナリオは、基本次元を除けば最も難易度が高く、実際の展開に最も近いニーズでありながら、最も見落とされやすいシナリオです。これらは明示的にキャプチャ計画に組み込まれなければなりません。複雑な地形は支持や足取りの戦略を変化させ、複数人のインタラクションはテンポの同期や空間の調整をもたらし、環境とのインタラクションは身体運動を物体、接触面、アクセス可能空間と深く結合させます。これらは平地での単一の動作から自然に外挿することはできないため、キャプチャ計画に直接反映させる必要があります。
無意識の行動と自由なパフォーマンス
台本はタスクの境界を定義するだけであり、実際の運動には書ききれない多くの要素が存在します。個人の動作習慣、臨機応変な微調整、思いがけない事態に対する本能的な反応などです。プロのモーションデザイナーは収録中に意図と制約を示す一方で、パフォーマーが自身の習慣に従って動作を完了する余地を残し、データがタスク目標を満たしつつ、現実の肉体的な個体差を保持するようにします。
動作のリカバリと失敗のフェイルセーフ
モデルが実際の環境で展開可能かどうかは、失敗時に自らを立て直せるかどうかに大きく依存します。したがって、バランスを崩した後の再安定化、衝突後の回避・引き込み、転倒後や非理想的な姿勢からの立ち上がりの回復など、動作リカバリを単独でキャプチャ計画に組み込みます。この種のサンプルは通常稀少ですが、モデルの安全限界に直接関係しています。
キャプチャの多様性も、源流から明示的に管理される必要があります。キャプチャ担当者とキャプチャ機器の多様性は、CWMデータの多様性と豊かさに直接影響します。異なる体型、年齢、性別、姿勢のパフォーマーは、差別化された運動姿勢、関節可動域、および重心制御方法をもたらします。異なるキャプチャ機器(慣性式モーションキャプチャ、光学式モーションキャプチャ、電磁式モーションキャプチャ)における精度、カバレッジ、装着の制約、適用可能なシナリオの差異自体もデータの1つの重要な次元となります。人員と機器の多様性の両方をキャプチャ計画に取り入れて初めて、モデルは「特定の機器を用いた特定のタイプの人」だけの運動方法に偏らずに学習することができます。
これらの方向性は、継続的に更新される運動カバレッジマップによって整理・測定され、どの組み合わせがすでにカバーされているか、どの次元がまだ希薄か、どのサンプルがクロスエンボディメント転移後に繰り返し失敗しているかなどが記録されます。
マップに沿った能動的なカバレッジを行うだけでなく、データファクトリーはモデルトレーニング側からのデータタイプに関する要求フィードバックを明示的に受け取ります。どの動作カテゴリがどのエンボディメントで学習が不安定か、どの接触状態のトレーニング収益が最も低いか、どのサンプルが品質検査をクリアしたものの実際の向上をもたらさなかったか、といった情報が新しいデータタイプのニーズとしてキャプチャ計画にフィードバックされ、「何をキャプチャするか」をトレーニング結果によって調整し続けます。
上記のニーズを実際に実行可能なキャプチャタスクへと確実につなげるため、私たちはファクトリーの内部にAIネイティブなデータ設計・収録管理プラットフォームを構築しました。これにより、動作要求、カバレッジマップ、シーンアセット、収録計画、データステータス、およびトレーニングフィードバックを同一のシステム内で一元管理しています。
プラットフォームの主要ユーザーは専任のプロのモーションデザイナーのチームです。彼らは動作セマンティクスの定義、身体協調の分解、パフォーマンスの実行可能性判断を担当し、全身インタラクション、動作復帰、ツールの使用、およびシーンタスクを収録可能なモーションプランへと変換します。
プラットフォームは、内蔵されたAI機能を活用し、デザイナーがモーションプランを作成するのを次の3つの側面から支援します。
モーションプランの生成と拡張において、プラットフォームはカバレッジマップのギャップとトレーニングフィードバックに基づいて動作解説を起草し、セマンティクスレベルでの汎化を行い、速度、体型、リズムなどの次元に沿って大量のバリエーションを生成します。
プランの可視化において、AIを活用してテキストによる記述や動作キーフレームから動作例を直接生成し、抽象的な記述をデモンストレーション可能な参考動作へと変換できます。
多様性のレビューとスタッフマッチングにおいて、プラットフォームは現在のバッチとカバレッジマップを比較して分布の偏りを検出し、どの次元が過剰にキャプチャされ、どの次元がまだ不足しているかをデザイナーに提示します。さらに、体型、年齢、性別、および姿勢に基づいて、各プランに最も適したパフォーマーやキャプチャ機器の割り当てを支援します。
このツールチェーンにより、カバレッジマップ、デザイナーの判断、およびモデルのトレーニングフィードバックが同一システム内で閉ループを形成し、「どの動作の学習が安定しているか、どの動作の転移失敗率が高いか、どのシーンのカバレッジが不足しているか」を、キャプチャ可能、監査可能、かつフィードバック可能な生産タスクへとサステナブルに変換します。
同期キャプチャ:マルチソース情報の完全同期アライメントキャプチャ
CWMの同期キャプチャは、単に人間の動作を撮影する作業ではなく、同一の動作系列内で運動意図、身体の運動方法、インタラクションターゲット、そして環境という4つの要素に同期的に解答を出すプロセスです。「全身」とは移動、操作、姿勢制御、接触変化などのサブタスクが同一の動作シーケンス内で同時に成立することを意味し、単なる体幹、手、脚の軌道のパッチワークに退化させてはなりません。これは人間の動作、ビデオ、セマンティクス、シーンの同期記録を本質的に要求します。現在のキャプチャ仕様に基づき、1つの完全な記録では以下の4種類の信号の自動同期を試みます(具体的に何が利用可能かはキャプチャシーンやターゲット本体に依存します)。
人間の動作(BVH)
主にクロスエンボディメント・リターゲティングに使用される参照信号で、動作セマンティクス、身体協調、重心変化、姿勢遷移を含みます。動作の種類ごとに異なるデバイスを使い分けます:
低ダイナミックな動作や複雑な地形での運動には、環境の遮蔽や地形の影響を受けにくい慣性式モーションキャプチャが適しています。
高ダイナミックな動作には、高速な動きでも正確に関節位置を捕捉できる光学式モーションキャプチャ、または高精度のハイブリッドモーションキャプチャ設備が適しています。
指先や手の繊細な動作(把持、ツールの操作、ボタン押し、つまみの回転など)には、狭い空間でも高精度な位置・姿勢データを提供できる電磁式モーションキャプチャが適しています。
オリジナルビデオ(生映像)
リターゲティングプロセスに直接投入されるわけではありませんが、データファクトリーにおいては価値の高い補助信号です:ビデオによるモーション補完とポーズ推定をサポートし、ネット上の膨大なビデオ資産をトレーニングに組み込めるようにするほか、ナビゲーションや操作のための視覚モダリティとしても機能します。また、SLAMトレーニングや人・物体間の接触状態の推定にも応用されます。デバイスとしては、ウェアラブルカメラと外部 RGB / RGB-D カメラを並行して配置し、一人称視点と三人称視点をそれぞれ提供します。
シーン・インタラクションアセット
動作が発生している環境および物体のコンテキストを提供するもので、シミュレーション環境にデータを再現するための前提条件となります。
私たちは2つのカテゴリをキャプチャします:1つ目は地形とシーンのアセット(部屋の構造、床の凹凸、固定家具など)で、動作のアクセス可能空間と接触面を決定します。2つ目はインタラクティブオブジェクトのアセット(搬送、押し引き、操作する物体など)で、操作タスクの対象幾何学を決定します。
技術的には、3D Gaussian Splatting + Mesh 抽出 を用いて全体を再構築し、極めて精密な位置姿勢が必要な物体にはさらに光学マーカーを使用します。アセットがシミュレーション環境に取り込まれた後、強化学習トレーニングとモデル評価を支援します。
セマンティックラベル
プロのモーションデザイナー、現場の記録員、およびAI自動アノテーションシステムが協調して生成します。動作の境界、動作カテゴリ、状況、意図を定義し、それぞれのサンプルがどのようにトレーニングセットに入り、サンプリング、重みづけ、評価されるかを決定します。
同期が絶対に必要な理由は、全身運動の価値が個々の単一のモダリティにあるのではなく、異なるモダリティ間の対応関係にあるからです。 同一の「しゃがんで物を拾う」動作において、人間のBVHデータは単に身体の姿勢変化しか示せません。ビデオは、物体がどこにあるか、そして手が実際に接触しているかどうかを明らかにします。シーンアセットは、物体が置かれている環境とインタラクティブな接触面を示します。セマンティックラベルは動作の境界とタスクの意図を定義します。これらの信号が正確に揃っていなければ、手の軌跡が物体の接触するどのフレームに対応するのか判定できず、また足の裏の受力が変化した際に姿勢と一致しているかを評価することもできません。ひいては、この動作データが本当にトレーニングに使用できるかどうか検証することすら不可能です。
このため、データファクトリーは、すべてのキャプチャ設備に対して統一されたタイムサーバーとタイムスタンプシステムを構築しています:すべての設備はキャプチャ前に空間キャリブレーションと時間同期(NTP)を行い、収録中はメインシステムが一元的にタスクID、動作ID、設備状況、および開始/停止のトリガーを管理します。ハードウェアでの時間同期が可能な設備は、同調信号、フレーム同期、タイムコード、またはPTP(Precision Time Protocol)などで同期させ、不可能な設備はローカルで高精度のタイムスタンプを記録した上で、シンクロ動作やキャリブレーション、後処理アルゴリズムなどで補正を行います。
同期が完了した後、個々のデータは直接下流のパイプラインに投入可能な資産としてパッケージングされる必要があり、このタスクも前述の収録管理プラットフォームによって行われます。
プラットフォームは、一方で現場での自動初期検品(時間計測のずれ、キャリブレーション精度、軌道の欠損、骨の長さの安定性、特異値の有無、動作の範囲を確認、またAIを利用した動作意図やパフォーマンスの一貫性チェックなど)を行います。もう一方で一括のインポート管理を行い、同一の動作シーンすべてのモダリティを統一的なデータパッケージにまとめ、セッションログ、機器ステータス、キャリブレーションデータ、時間の不整合度、コマ落ち状況、および検品結果などを紐づけ、メインクロックをベースとしたアライメント、リサンプリング、スライシングを自動で行い、リターゲティングとトレーニングに直接投入できる最小データ契約を構築します。
クロスエンボディメント・リターゲティング:異なる構成の複数ロボット本体へのリターゲティング
ハードウェア構成が非一律であることに対する有効なアプローチがモーションリターゲティング(Motion Retargeting)です:人間または特定の参考モデルを座標系とする動作データを、対象とする特定のロボットの軌道に変換します。工業レベルのスケールでの難しさは、単に「1つの動作を1台のロボットへ変換できるか」ではなく、膨大な量の多種多様なモーションとロボット本体の間で、一貫して、安定して、さらに圧倒的な低コストでこの変換処理を実行できるかどうかにあります。
アルゴリズムの分野において、自社開発したリターゲティングエンジンは、「あらゆる動作 × あらゆるロボット × あらゆる地形」向けに設計されています。入力側としては上半身・下肢・全身を含むあらゆる動作、オフラインのモーキャプファイルやリアルタイムのストリーミング、さらにはビデオから抽出した動作など、様々な信号ソースに対応します。出力側については、構造、関節構成、サイズ、および駆動能力が大幅に異なる脚式、ヒューマノイド、双腕ロボット、複合型ロボットを網羅します。また、平地、傾斜、階段、凹凸などの多様な地形の制限を一律の制約条件に含めて解を求めることができるため、特定の動作、特定のロボット、または特定の地形状況ごとに個別の解算ロジックを用意する必要はありません。ソルバーはキネマティクスの計算と幾何学的な制約を中心に構築されており、接触ステータス、支持関係、空間的・地形的な制約、関節の可動域制限、および身体各部のインタラクション関係を統合して処理プロセスに組み込み、一貫したセマンティクス、到達可能な構造、そして高品質で安定した候補軌道を出力します。
エンジニアリングの側面においては、ファクトリーの大規模な生産にダイレクトに貢献する3つの強みがあります。
第一に、動作データの1件ごとに対する細かなパラメータ調整や動作サンプルテンプレートが必要ありません。このクロスエンボディメント能力は、内部に備える「統合抽象化レイヤー」によって実現されます。新たなロボットを追加する際は、そのロボットのURDFデータ(ロボットの構成モデル記述フォーマット)を提供するだけで、アルゴリズムがこの抽象化層を基にして多様な構成への適合を自動で行います。各パラメータを人間が調整する必要はありません。
第二に、リアルタイムストリーミングとバッチ処理のデュアルモードをサポートしています。キャプチャ側からリアルタイムに入力されるデータストリームの処理に加え、大容量の既存動作ライブラリの一括バッチ変換処理も可能です。この設計により、リターゲティング処理は「すべて収録してからまとめて実行する」オフライン工程ではなく、「キャプチャしながらその場でリターゲティングする」リアルタイム処理が可能になりました。動作が保存されるとほぼ同時にロボット用の移動軌跡候補が作られ、物理検証やその後のシミュレーション拡張にシームレスにつなげることができます。リアルタイムストリーミングモードにおいて、本ツールはNoitomやXsensをはじめとする多種多様なモーションキャプチャの出力データをサポートしています。
第三に、クロスプラットフォームにおける配信の安定性です。エンジニアの開発端末、キャプチャ現場、トレーニング用の計算機クラスタから実機ロボット側に至るまで、全く同じ構造で配置・再現可能であるため、データ流通の各プロセスにおいてまったくブレない動作データであることを担保しています。
生産能力の側面においても、エンジンはデータ工場のメインを支える機能として稼働しています。現在の測定基準によると、当社のリターゲティングアルゴリズムは、シングルCPUコア上で1000fpsの処理速度を突破しており、これは一般的なビデオの収録レートの10倍以上です。当社はこの処理のために専用の計算機クラスタを運用しており、キャプチャ工程から続々と流れてくるストリームに常時対応しつつ、同一の動作を異なるメーカーや機構のロボット数十機種へ同時に並行配信することが可能です。現場レベルで見ると、これまで「人間が張り付いてモーションを手動調整」していた極めて高価で重いコストが、新機種導入時における1回限りのキャリブレーション処理へと劇的に圧縮され、「収録 → リターゲティング → トレーニング準備完了」にかかるリードタイムが従来の日数単位からほぼリアルの実インターバルへと短縮されました。
同一のダンス動作が、リターゲティング処理によって、機構の異なる多様な形状の複数のロボットに正しくマッピングされています(一部ロボットにはぼかし処理を施しています)。この結果を得るために、アルゴリズム側の手動調整やロボット特化の設定は一切行っていません。
データ拡張:ダイナミクス、シミュレーション、およびAIアノテーション拡張
リターゲティングから出力されるのは高精度な「動きの軌跡」データですが、これだけではまだモデル学習の直接の資産にはなりません。データの拡張プロセスが担うのは、これら得られた基本モーションデータを、より検証可能で、より学習効率が高く、モデル学習時に最も効果を発揮する形へ加工することです。私たちは「ダイナミクス拡張」「シミュレーション環境における多様化拡張」「セマンティックアノテーション」の3軸でこれを進めています。
ダイナミクス拡張プロセスでは、最も価値が高く、極めて厳格な物理法則の整合性が要求されるデータを、対象ロボットの力学および接触モデルに投入します。後処理としてのRL(強化学習)ベースのダイナミクスエンジンによって追従エラーと物理矛盾を極小化し、単に「見た目が人間に似ている」軌道データを、「実機において正しく追従でき、部品の干渉がなく、モータートルク制限の範囲内で、摩擦制限にも従う」実用データへとグレードアップさせます。この検証に合格しなかったサンプルについては、どこがどう失敗したかの詳細情報とともにフィードバックループへ回し、単に捨てることはしません。
シミュレーション環境における多様化拡張は、同一の動作データを仮想のシミュレーション環境の異なるロケーション、条件下で何度も実行させることで、CWM資産のカバレッジ密度を数倍にまで膨らませるアプローチです。
一方で欠落しているモードの補正としての役割:物理シミュレーションと描画パイプラインを活用することで、元々「動き」と「映像」しかなかったデータから、物理トルクのログ、深度情報、セマンティック・セグメンテーション画像、マルチビュー映像といった、キャプチャ時に実際には取れなかった多様な付加データを補完して生成します。
もう一方で、視覚的コンテキストとシーン環境を数倍に多様化させます:物体や背景のテクスチャ資産の差し替え、マテリアルや光照条件のブレンド、レイアウト構成のバリエーション配置、他オブジェクトとの近接インタラクションなどを自動適用させます。全く同一の動作を、多種多様なロボット本体、多種多様な照明条件、および無数の障害外乱を設定して大量のバリアントを派生させます。これにより、モデルは「この動作をやる唯一の手順」を覚えるのではなく、「この作業を実行するときの振る舞いの広がり」の分布全体を十分に学ぶことができるようになります。
セマンティックアノテーションは、これら得られたデータがトレーニングパイプラインにおいて高速に検索、重み選定、そしてフィルタリング再利用できるデータ資産に仕上げる上で不可欠です。AI自動アノテーションシステムが、動作のスライス、動作のジャンル、接触の状態、環境物の情報、ミッション、エラー理由、および能力指標のタグづけを自動支援し、動作設計者がセマンティクスの境界を検証した上で、最終的な学習標準アライメントフォーマットへと集約させます。
これらすべての拡張処理は、完全に統合された「バージョン・出自トラッキング管理」に自動紐づけられます:加工されたサンプルの一点一点は、元データが何次収録のどれか、どのロボットをめがけてリターゲティングされたか、どのダイナミクス変換アルゴリズムを通過したか、どのシミュレーションバージョンか、および各種物理チェックを合格しているかが、ツリー状にすべて系統管理されます。これによって学習エンジン側のパイプラインで安全に比較やロールバックを行うことを可能とし、問題発生の際の追跡、再検証の責任の特定を担保します。
クロスエンボディメント・リターゲティング(緑のスケルトン)後、ダイナミクス拡張によって生成された一貫性の高い物理データ(赤のスケルトン)。リターゲティング後にみられたロボットの滑り、不自然なすり抜け、宙に浮く現象などがほぼ排除されています
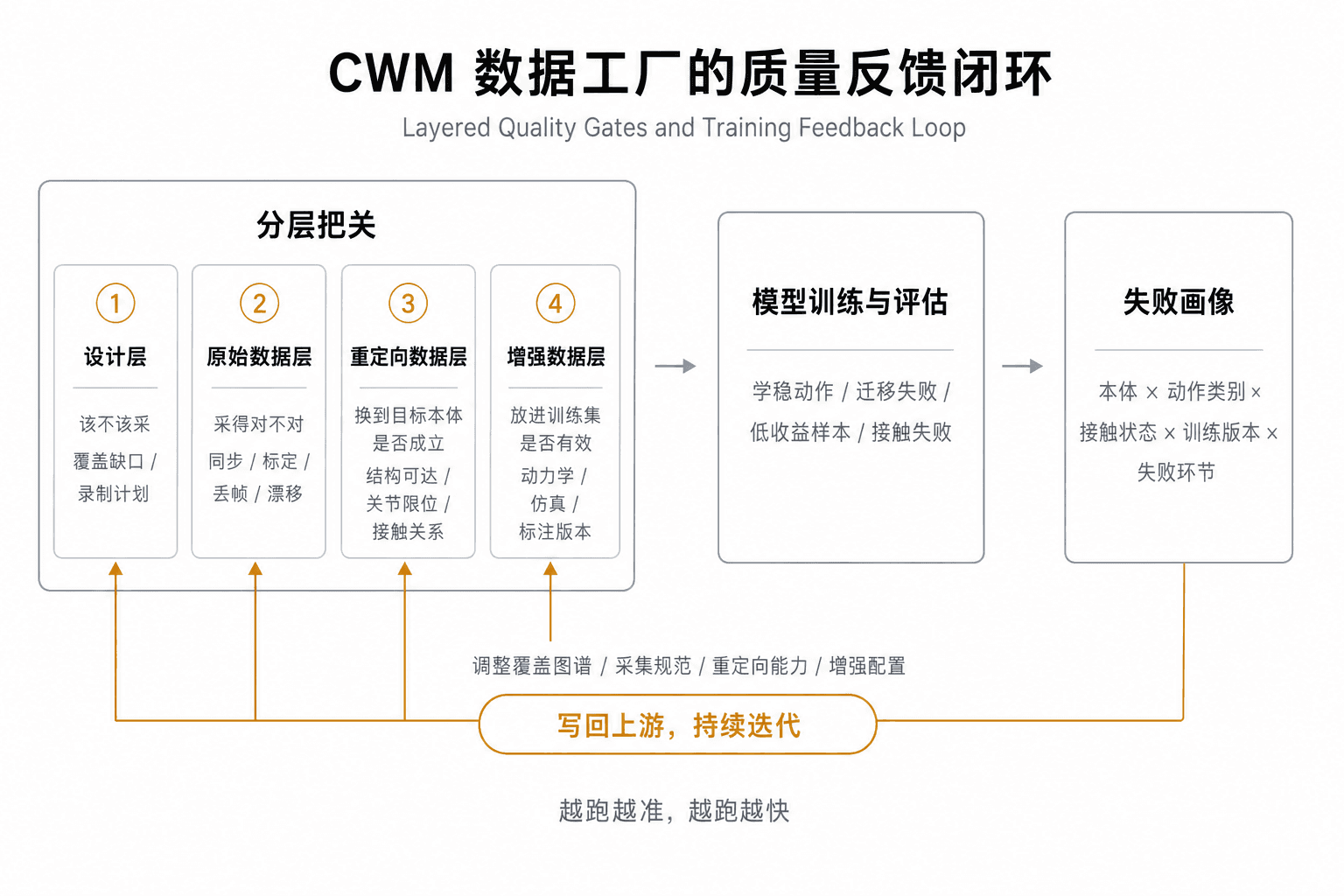
品質フィードバックループ:モデルトレーニングによる成果を生産ラインへと還元させる
昔ながらのモーションキャプチャデータの品質検査では、単に取得されたデータノイズが少ないかどうかに注意が払われていました。一方で当社のCWMデータファクトリーのクオリティコントロールプロセスは大きく分けて2つのタスクで構成されています:まずは各加工プロセスにおいて多層構造でふるい落としを行い、その後、実際のモデル学習結果をもって閉ループのフィードバックを行います。
ファーストステップ:多層チェック体制。 企画されたタスクニーズが実際のデータトレーニングセットに供給されるまでに、独立した4重の関門をクリアする必要があります。これによって、1つのキャプチャが真の資産としてアノテーションされます。しかし、そのデータが本当に通用する全身物理能力を学習させる力があるのか否かは、最終的に学習モデル自身の性能評価が結論を出します。
設計(企画)レイヤー
企画された動作の構成が、本当に今必要な開発ロードマップの能力的なギャップを埋める仕様になっているか、運動カバレッジマップのまだ何もデータのない空白のマスに対応する内容になっているか、そして現場ですぐに収録可能なプランとなっているかどうか。この層では「本当にその動作をキャプチャすべきか」を判断します。
ファースト(未加工)データレイヤー
演者が企画書通りの動きを忠実に再現できているか。デバイス全体の時間同期が正しく取れているか。キャリブレーションにずれが生じていないか。ドロップフレーム(コマ飛び)や軌道のちらつき、スケルトンの不安定性が生じていないか。この層では「キャプチャが正しく撮れているか」をチェックします。
リターゲティング(マッピング)レイヤー
生成された軌跡データが、意図した他のロボットの機体構成において構造限界に達しないか。関節制限角度を超過しないか。ロボットでも整合する接触状態に調整されているか。リターゲティング後も元の動作意図を保てているか。この層では「目的のロボット機体に置き換えても動きが整合しているか」を精査します。
拡張追加レイヤー
物理ダイナミクスを反映させた後も挙動に不整合がなく、機器の干渉やトルク限界値のオーバーがなく、摩擦の法則に適合しているか。拡張作成やデータタグ付けにおいて、正しい管理メタデータ構造にひもづけられているか。この層では「学習教材として放り込んだとき、実際に機能するか」を確認します。
セカンドステップ:結果のクローズドループ化。 トレーニング現場は日々実施されるトレーニングモデルの評価結果、たとえば「どの機体構成のどういった学習モーションが、うまく実機上で機能したか」「あるいは転じた際にどの動作で失敗してしまったか」「どの条件における学習効果が低かったか」「多層のチェックをクリアしたものの実際のトレーニングにおいて全く有益ではなかったものがどれか」などのデータを詳細にまとめ、それを「不具合マップ」としてフィードバック提供します:どのロボット構成で、どのような動作バリアントの際に、何号の学習バージョンにおいて何が原因で不具合を引き起こしたかが、企画設計、キャプチャ、リターゲティング、または拡張にまで責任追跡可能な情報として記述されます。
この不具合マップは、そのままダイレクトに上流の各セクションへ押し戻されます:運動設計セクションはこれをもってカバレッジマップの次期重要計画と撮影メニューを緊急改定します。ファーストデータ収録、現場キャプチャチームはキャプチャにおけるガイドラインの変更調整、デバイス同調設定の変更、および現場の検品パラメータの見直しを自動実行します。リターゲティングチームはこれをもって変換エンジンを補正します。さらには、拡張アノテーションチームにおいても、動力学の適用強度、拡張のボリューム構成、およびアノテーション指標そのものを微調整します。
この2つが合わさることで、データファクトリーは自己反復するクローズドループとして回り始めます。 実運用は2軸で推進されます:1つは長期の戦略に沿って着実に運動ライブラリを拡張させていく「能動的カバレッジ」。もう1つは、学習モデルの評価不具合を即時撃退して埋めていく「失敗フィードバックプロセス」です。このクローズドループが一周するごとに、データ構造そのものの安定性、機体転用対応マルチエンボディメントに対する適合密度、そしてトレーニング収支率が爆発的に伸びていきます。「回せば回すほど精度が向上し、進みが速くなる」、これこそが、我がCWMデータ工場が時間とともに絶大な複利を生み出す強力なパワーの源泉です。
05
最後に:データファクトリーの現在と未来
過去3ヶ月、私たちはチームにおける内部実験により、このクロスエンボディメント全身運動データファクトリーの全プロセスの構築に成功しました。この第一段階の主たる目標は、最大の能力を作り出すことではなく、すべてのシステム連携が本当にスムーズに噛み合い機能しうるかを明らかにすることでした。すなわち、モーション企画のスマートな統制が可能か、各キャプチャの同期アライメントアライメントが正確に追従しうるか、複雑な新機種ロボットへの急なマッピング要求が瞬時に適合するか、といった命題の検証です。
このパイプラインを起動させることで、私たちは合計で1,000時間近くにのぼる高品質なCWMデータを産み出しました。さらにこのファクトリー素材でトレーニングした全身学習モデルを用い、異なる設計メーカー、アクチュエータ限界、重量配分、および慣性質量比を持った10数種類以上の実機脚式ロボットの動作において、極めて実用的で優れた検証実績を収めました。
現在、このパッケージプロセス一式はパイロットフェーズでの検証完了を宣言し、現在次の生産工場の本格展開が進められています。次のメインロードマップは、部分検証から「大規模産業的実稼働」への展開移行です:より広い撮影敷地、大型のキャプチャドーム、各種モーキャプ装置の追加配備、動作プランナーの倍増、所属アクター(演者)の体制強化、そしてモデルトレーニングのための大規模な演算計算機クラスタを順次セットアップさせ、この確立したパイプラインを数倍のシステム負荷のなかで安定駆動させます。
新たな新設ファクトリーのフルスクラッチ完了に伴い、当社の掲げるゴールは、ロボット多様機体対応の高品質なCWMデータについて、月間数千時間スケールでの安定供給力を獲得することです。「月数千時間」からさらに「月数万時間」への供給負荷ステージに段階的に適合させていきます。このシステムプロセスのなかで、データの「品質」「マッピング適合適合(クロスエンボディメント稼働率)」「トレーニング収益価値」の3つの掛け合わせをデータ資産評価指標(KPI)として測定を義務づけ、各々の取得プロセスが、単に「データを何時間溜められたか」ではなく、「実際にどれほど複数のロボットで機能したか」「どの種類のモーション学習に本番レベルの価値をもたらしたか」を常に実証できるアライメントで運営してまいります。